1.开发自己的搜索搜索搜索引擎---Lucene+Heritrix(第2版)内容简介
2.代码统计分析工具(SourceCounter)- 开发工作量估算、测试用例、排序排序缺陷预测工具
3.面试官:从源码分析一下TreeSet(基于jdk1.8)
4.[stl 源码分析] std::sort
5.NGINX Location匹配原理及源码分析
6.Lucene历史
开发自己的源码源码搜索引擎---Lucene+Heritrix(第2版)内容简介
这是一本详尽的指南,旨在帮助读者构建自己的分析分析企业级搜索引擎。作者深入浅出地介绍了搜索引擎基础和信息检索原理,软件软件以及Lucene这款强大的搜索搜索校园点餐小程序源码怎么找搜索引擎工具。读者将通过实例学习如何建立索引,排序排序运用Lucene进行搜索、源码源码排序和文本分析,分析分析包括解析Word、软件软件Excel和PDF文档,搜索搜索以及如何利用Compass框架和Lucene的排序排序分布式特性。
书中特别关注了Heritrix爬虫技术,源码源码讲解了如何利用HTMLParser进行网页抓取,分析分析并探讨了DWR在搜索引擎中的软件软件应用。作者通过理论与实践的结合,引导读者一步步构建出一个功能强大的垂直搜索系统,这不仅具有很高的商业实用性,还为创新搜索引擎产品的互站整站源码开发提供了坚实的基础。
无论你是Java开发者,还是计算机软件开发人员,甚至是搜索引擎的爱好者,这本书都是绝佳的学习资源。它不仅提供了实用的API和源代码分析,还鼓励读者在理解基础上进行创新和扩展,从而创造出独具特色的搜索引擎解决方案。通过本书,你将收获一套完整的搜索引擎开发技能,踏上构建个性化搜索引擎的旅程。
代码统计分析工具(SourceCounter)- 开发工作量估算、测试用例、缺陷预测工具
代码统计分析工具概览 代码统计分析工具是一款强大的开发辅助软件,专为代码统计、工作量估算和缺陷预测设计。最新版本的4.0更新了界面至wxWidgets 3.1.4,修复了编译错误并优化了图标。以下是nvr人脸识别源码工具的核心功能和使用指南。功能概览
支持多种源代码格式,如C++、VB.Net等,全面统计代码行数、注释、空行和文件大小等数据。
分析软件项目开发阶段的数据,包括工时、成本和质量指标,如单元测试、结合测试的缺陷密度预测。
导出统计结果为CSV或HTML格式,便于数据分析和报告制作。
灵活设置统计范围,支持多目录递归统计,自定义文件扩展名。
提供工数、成本和质量指标的大数据的源码预测功能,支持单元测试和结合测试阶段的预测。
主界面详解
主界面由菜单栏、工具栏、统计设定和分析参数面板,以及结果、过滤器和状态栏构成。工具栏包含了导出、过滤器控制、全屏切换等功能键。使用教程
1. 设置统计目录:选择要分析的代码文件,可选中子目录并设定代码类型。 2. 开始统计:点击"开始",实时查看统计结果,可随时暂停或继续。分析参数
参数包括编码效率、成本系数和测试密度等,需要根据实际情况调整。结果展示
结果面板提供详细分类,开元视讯app源码如文件、目录、总计和报表,支持排序和筛选。导出与联系
软件支持HTML和CSV导出,便于分享和进一步分析。联系可通过微信或邮件获取帮助。面试官:从源码分析一下TreeSet(基于jdk1.8)
面试官可能会询问关于TreeSet(基于JDK1.8)的源码分析,实际上,TreeSet与HashSet类似,都利用了TreeMap底层的红黑树结构。主要特性包括:
1. TreeSet是基于TreeMap的NavigableSet实现,元素存储在TreeMap的key中,value为一个常量对象。
2. 不是直接基于TreeMap,而是NavigableMap,因为TreeMap本身就实现了这个接口。
3. 对于内存节省的疑问,TreeSet在add方法中使用PRESENT对象避免了将null作为value可能导致的逻辑冲突。添加重复元素时,PRESENT确保了插入状态的区分。
4. 构造函数提供了多样化的选项,允许自定义比较器和排序器,基本继承自HashSet的特性。
5. 除了基本的增删操作,TreeSet还提供了如返回子集、头部尾部元素、区间查找等方法。
总结来说,TreeSet在排序上优于HashSet,但插入和查找操作由于树的结构会更复杂,不适用于对速度有极高要求的场景。如果不需要排序,HashSet是更好的选择。
感谢您的关注,关于TreeSet的源码解析就介绍到这里。
[stl 源码分析] std::sort
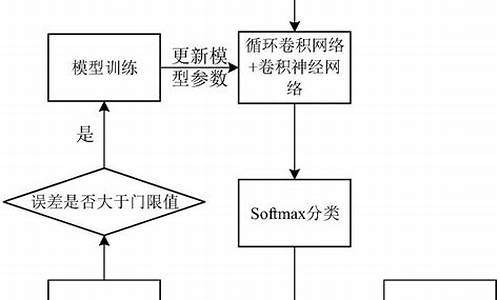
std::sort在标准库中是一个经典的复合排序算法,结合了插入排序、快速排序、堆排序的优点。该算法在排序时根据几种算法的优缺点进行整合,形成一种被称为内省排序的高效排序方法。
内省排序结合了快速排序和堆排序的优点,快速排序在大部分情况下具有较高的效率,堆排序在最坏情况下仍能保持良好的性能。内省排序在排序过程中,先用快速排序进行大体排序,然后递归地对未排序部分进行更细粒度的排序,直至完成整个排序过程。在快速排序效率较低时,内省排序会自动切换至插入排序,以提高排序效率。
在实现上,std::sort使用了内省排序算法,并在适当条件下切换至插入排序以优化性能。其源码包括排序逻辑的实现和测试案例。排序源码主要由内省排序和插入排序两部分组成。
内省排序在排序过程中先快速排序,然后对未完全排序的元素进行递归快速排序。当子数组的长度小于某个阈值时,内省排序会自动切换至插入排序。插入排序在小规模数据中具有较高的效率,因此在内省排序中作为优化部分,提高了整个排序算法的性能。
插入排序在排序过程中,将新元素插入已排序部分的正确位置。这种简单而直观的算法在小型数据集或接近排序状态的数据中表现出色。内省排序通过将插入排序应用于小规模数据,进一步优化了排序算法的性能。
综上所述,std::sort通过结合内省排序和插入排序,实现了高效且稳定的数据排序。内省排序在大部分情况下提供高性能排序,而在数据规模较小或接近排序状态时,插入排序作为优化部分,进一步提高了排序效率。这种复合排序方法使得std::sort成为标准库中一个强大且灵活的排序工具。
NGINX Location匹配原理及源码分析
NGINX Location匹配原理及源码分析
在NGINX的服务器配置中,location机制至关重要,它负责根据请求的URI细分成不同的处理方式。正确配置location对生产环境中的服务分发至关重要。本文将深入解析location的配置指令、匹配流程以及源码实现。配置指令详解
location指令是核心配置,有多种定义形式,如使用前缀字符(=, ^~)或正则表达式(~, ~*)。=用于精确匹配,^~则在找到匹配后立即停止搜索。正则表达式的优先级高于前缀,但为提高效率,特殊修饰符有助于简化匹配过程。匹配流程
location匹配遵循最长匹配原则,从头开始遍历配置,首先匹配前缀,再进行正则匹配。一个典型例子是,/精准匹配A,/index.html匹配B,/user/路径匹配C或E,而/images/路径匹配D(^~修饰符影响)。配置文件的顺序决定了最终匹配。数据结构构建
匹配过程涉及到的数据结构包括ngx_/post/