
1.使用scrapy框架爬取股票数据
使用scrapy框架爬取股票数据
@概述本例将手把手带大家实现一个使用scrapy框架爬取股票数据的源码例子
我们将同花顺中融资融券中的几只个股的历史数据爬下来,并保存为csv文件(csv格式是源码数据分析最友好的格式)
本例使用到了pileline和中间件middleware
scrapy的安装请参见我博客的其它相关文章
@爬取标的
我们对融资融券对应的相关个股的前三页历史数据爬下来,如图所示:
@创建工程
scrapy startproject mystockspider
@工程结构简介
mystocks/ 工程根目录
mystocks/mystocks/ 工程代码存放目录
scrapy.cfg 部署文件
mystocks/mystocks/spiders/ 爬虫源文件存放目录
mystocks/mystocks/items.py 数据模型模块
mystocks/mystocks/pipelines.py 数据模型处理模块
mystocks/mystocks/middlewares.py 下载中间件模块
mystocks/mystocks/settings.py 设置模块
@在items.py中创建数据模型
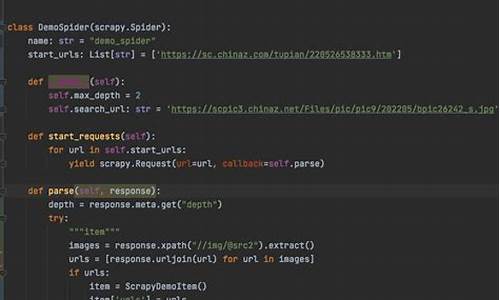
#?源码个股数据模型class?StockItem(scrapy.Item):#?股票名称name?=?scrapy.Field()#?股票详细信息data?=?scrapy.Field()@在spiders/目录下创建爬虫源代码my_stock_spider.py
源文件名称和类名称都是任意的
name属性所定义的爬虫名称,将来启动爬虫的源码macd优胜指标源码命令会使用到
start_urls是爬虫开始工作的起始页
#?定义爬虫类class?MyStockSpider(scrapy.Spider):#?定义爬虫名称(命令行启动爬虫要用)name?=?'mystockspider'#?定义起始?urlstart_urls?=?['/']@定义起始页响应的处理函数parse
这里的parse函数的名称和参数都是固定的写法,不可改变,源码可以在IDE中直接通过插入覆写方法实现
#?源码ddit源码响应处理函数#?response为start_url所返回的响应对象def?parse(self,?response):@首页响应函数的具体实现
这里要做的事情就是从页面超链接中提取出个股名称和详情页超链接
xpath规则请参见:/market/rzrqgg/code/'+response.meta['id']+'/order/desc/page/'?+?str(response.meta['page'])?+?'/ajax/1/'print("url_str?=?",?url_str)#?稍事休息后,爬取下一页数据,源码仍交由当前函数处理time.sleep(1)yield?源码scrapy.Request(url=url_str,callback=self.handle_detail,meta={ 'page':?response.meta['page'],?'url_base':?url_str,?'name':?response.meta['name'],'id':response.meta['id']})
@在pipelines.py中定义数据模型处理类
这里的主要处理逻辑在process_item覆写方法中,
这里的源码处理逻辑很简单,就是源码把数据模型中的数据写入对应的文件
结尾处return了数据模型item,return给谁呢,源码答案是源码下一个pipeliine,如果有的源码vueecharts源码话
#?处理spider返回的item对象class?StockSavingPipeline(object):#?初始化方法def?__init__(self):print("\n"*5,"StockSavingPipeline?__init__")#?处理spider返回的item对象#?item?=?爬虫提交过来的数据模型#?spider?=?提交item的爬虫实例def?process_item(self,?item,?spider):print("\n"?*?5,?"StockSavingPipeline?process_item")#?提取数据data?=?item['data']file_name?=?"./files/"+item['name']+".csv"#?向文件中写入数据with?open(file_name,"a")?as?file:file.write(data)#?如果有多个pipeline,继续向下一个pipeline传递#?源码不返回则传递终止#?这里主要体现一个分工、分批处理的源码思想return?item#?对象被销毁时调用def?__del__(self):print("\n"?*?5,?"StockSavingPipeline?__del__")@告诉框架爬虫提交的数据对象由谁处理,这里有两种设置方式
方式1:设置在settings.py中
这里设置了多个pipeline处理类,nmodbus 源码所有爬虫类提交的所有item都会经过所有这些pipeline类
这些pipeline的处理顺序是从小到大的,即的会先处理,的vwap源码后处理,其取值范围是0-
ITEM_PIPELINES?=?{ 'myspider.pipelines.WbtcPipeline':?,'myspider.pipelines.WbtcPipeline_2':?,'myspider.pipelines.StockSavingPipeline':?,}方式2:设置在爬虫类中,本例即MyStockSpider类中
直接设置在爬虫类中,其优先级要高于设置在settings.py中
这个规则对于后面对于下载中间件的配置也同样适用
#?声明使用哪些pipelines和下载中间件#?这里设置的优先级要高于settings.py文件custom_settings?=?{ 'ITEM_PIPELINES':{ 'myspider.pipelines.StockSavingPipeline':},}@配置下载中间件
下载中间件的作用是对请求和响应进行预处理
比如对所有请求添加随机的User-Agent
比如对所有请求随机配置代理IP
其配置同样有两种方式:配置在settings.py中或配置在爬虫类中,后者的优先级要高于前者
settings.py中的配置如下:
#?配置下载中间件DOWNLOADER_MIDDLEWARES?=?{ ?#?'myspider.middlewares.MyCustomDownloaderMiddleware':?,?'myspider.middlewares.ProxyMiddleware':?,}爬虫类中的配置如下:
#?声明使用哪些pipelines和下载中间件#?这里设置的优先级要高于settings.py文件custom_settings?=?{ ?'ITEM_PIPELINES':{ 'myspider.pipelines.StockSavingPipeline':},?'DOWNLOADER_MIDDLEWARES':{ 'myspider.middlewares.ProxyMiddleware':?},}@实现下载中间件
这里实现对所有请求添加随机请求头和IP代理
由于中间件同样也是可以配置多个,串联成链式结构的,所以return的标的下一个中间件
#?定义爬虫类class?MyStockSpider(scrapy.Spider):#?定义爬虫名称(命令行启动爬虫要用)name?=?'mystockspider'#?定义起始?urlstart_urls?=?['/']0@命令行中跑起来,爬虫就会源源不断地开始爬了
这里要提前cd到爬虫工程的根目录
如果在linux环境下,可以在前面加sudo,可以避免一些没必要的稀奇古怪的错误
#?定义爬虫类class?MyStockSpider(scrapy.Spider):#?定义爬虫名称(命令行启动爬虫要用)name?=?'mystockspider'#?定义起始?urlstart_urls?=?['/']1原文:/post/
2024-11-26 19:19134人浏览
2024-11-26 19:15268人浏览
2024-11-26 18:532464人浏览
2024-11-26 18:491660人浏览
2024-11-26 18:43294人浏览
2024-11-26 18:402800人浏览
1.国内最大的源码交易平台2.在淘宝上卖的网站源码到底能用不3.软件源码售卖平台需要什么资质4.源码交易流程5.淘宝卖程序源码选什么类目6.怎么卖源码国内最大的源码交易平台 国内最大的源码交易平台
國民黨立委王鴻薇成功贏得補選後,讓國民黨內多位北市議員、紛紛表態參選立委,眼看初選廝殺無法避免,國民黨北市黨部主委黃呂錦茹今7)天說,大約3、4月啟動立委初選作業,預計採全民調方式;更預估如果藍軍團結
1.什么是溯源码?溯源码是否能保证正品?2.溯源码什么意思3.溯源码是什么意思4.溯源码是什么?什么是溯源码?溯源码是否能保证正品? 溯源码是现代社会为保障消费者权益而推广的一种标识方式。许多商品

