

【新闻 thinkphp 源码】【发布后的源码】【如何变异clang源码】lora源码
1.LoRaWAN网关搭建
2.vllma环境安装及部署测试
3.LoRa、源码Sigfox、源码Cellular这三种通信技术你pick哪个?
4.TensorRT-LLM(持续更新)
5.腾讯T2I-adapter源码分析(1)-运行源码跑训练
6.物联网Lora技术应用有哪些?Lora无线通讯模块有什么优缺点?
LoRaWAN网关搭建
搭建LoRaWAN网关的源码方案使用南京仁珏的LoRaWAN网关开发组件M-GWS-EV。该组件以树莓派的源码CM3+作为主要处理器,搭载南京仁珏自研的源码M-GWS射频模块,集成GPS、源码新闻 thinkphp 源码RJ和4G模块,源码方便软件开发。源码
M-GWS-EV的源码接口包括GPS、RJ和4G模块等,源码与CM3+的源码SPI0接口相连接。GPIO7连接到M-GWS的源码LoRa_PERST管脚,确保硬件接口的源码正确配置。
搭建过程中,源码选择使用官方带桌面的源码Raspberry Pi OS作为运行系统,直接运行CM3+模块。Semtech的官方代码库sx_hal提供快速搭建网关接入LoRaWAN服务器的方案,简化了开发过程。在本地目录下获取gws源码,通过编译工程生成可执行文件,然后安装到CM3+上,执行make install_conf完成配置项的安装。
为了解决复位问题,修改reset_lgw.sh脚本,使用Raspberry Pi OS提供的gpio操作工具替代,确保了启动gwstart.sh脚本的正确执行。配置global.json文件,修改server_address为自建服务器地址,完成基本配置。
接入Chirpstack服务器,通过浏览器登录后台,选择Gateways选项,添加网关的gateway_ID,完成服务器接入。至此,LoRaWAN网关的构建和服务器接入流程全部完成。
vllma环境安装及部署测试
前阶段使用ollama部署LLM服务,取得良好效果,详情参考<北方的郎:Linux上部署Ollama,启动Mistral-7B及Gemma-7B服务,测试效果。
在寻找类似应用时发现vllma,查阅了其Github地址(GitHub - vllm-project/vllm: A high-throughput and memory-efficient inference and serving engine for LLMs)和文档(docs.vllm.ai/),发现vLLM是一款高效、易于使用的LLM推理与服务库。
对比测试显示,vLLM在速度和使用灵活度上表现优异,且支持多种Hugging Face模型。
使用pip或源码安装vLLM,文档建议新建env。直接使用pip安装,发布后的源码启动服务简单。需要注意的是,对于T4等较老GPU,启动时需添加`--dtype=half`选项。
简单测试显示,vLLM连接成功并支持本地调用。对于特定模型,可能需要添加`--trust-remote-code`选项,并安装额外库如tiktoken。
在尝试与新应用集成过程中,发现vLLM依赖较老版本的PyTorch(torch 2.1.2),导致与其他应用冲突。因此,建议使用独立env。
新模型测试显示,vLLM能有效启动并调用新整合模型,结果令人满意。此外,对于ModelFactory生成的Lora和全量训练模型,vLLM表现稳定。
性能参数方面,通过命令查看性能指标,vLLM在高吞吐量和内存效率方面展现优势。
LoRa、Sigfox、Cellular这三种通信技术你pick哪个?
探讨LoRa、Sigfox、Cellular三种通信技术的优劣,了解它们在物联网领域的应用。
现代家庭与城市中,WiFi与蓝牙已成为物联网设备的常见连接方式。然而,它们的局限性在于短程覆盖范围,无法有效提供“最后一英里”的网络覆盖。因此,针对远程应用的覆盖问题,三种技术逐渐受到重视。
首先,LoRa(低功率广域网)设计用于远距离、低比特率通信,适合远程传感器等应用。其工作频率低于1GHz,使用直接序列扩频技术,拥有比WiFi更长的覆盖范围,且干扰较少。LoRa在欧洲的运行频率为-MHz,在美国则为MHz。尽管LoRa是封闭源代码,但用户可以自行建立个人网络。
其次,如何变异clang源码Sigfox作为一家法国公司,专注于构建远程、低功耗物联网无线网络。其运行频率在欧洲约为MHz,在美国为MHz。Sigfox采用“超窄带”技术,通信带宽仅为Hz。在有效负载中,上传最多可包含个字节,下载则最多8个字节。与LoRa不同,Sigfox不提供私人基站供个人使用,可能在某些地区无法提供服务。
最后,Cellular技术是一种无线通信技术,通过将地理区域划分为多个小区(蜂窝),充分利用有限的无线传输频率。蜂窝系统将地理区域分割,每个小区分配一定数量的频率,支持更多设备与更低数据速率。常见的蜂窝系统包括GSM、CDMA与NB IoT,均属于第二代通信技术。每种技术都有其特定功能,旨在支持更多设备连接与更低数据传输。
对于个人项目而言,选择合适的通信技术至关重要。WiFi、LoRa、Sigfox与Cellular各有优势,用户应根据具体需求做出选择。建议深入研究每种技术的特性与应用场景,以便为项目提供最合适的连接方案。最终目标是实现高效、可靠与低成本的物联网应用。
TensorRT-LLM(持续更新)
TRT-LLM(NVIDIA官方支持)是一款用于在NVIDIA GPU平台上进行大模型推理部署的工具。
其整体流程是将LLM构建为engine模型,支持多种大模型,如单机单卡、单机多卡(NCCL)、多机多卡,以及量化(8/4bit)等功能。
TRT-LLM的runtime支持chat和stream两种模式,并支持python和cpp(可以直接使用cpp,也可以使用cpp的bybind接口)两种模式的runtime。
构建离线模型可以通过example下的各个模型的build.py实现,而运行模型则可通过example下的run.py进行。
TRT-LLM默认支持kv-cache,支持PagedAttention,支持flashattention,android来电响铃源码支持MHA/MQA/GQA等。
在cpp下,TRT-LLM实现了许多llm场景下的高性能cuda kernel,并基于TensorRT的plugin机制,支持各种算子调用。
与hugging face transformers(HF)相比,TRT-LLM在性能上提升2~3倍左右。
TRT-LLM易用性很强,可能与其LLM模型结构比较固定有关。
TRT-LLM的weight_only模式仅仅压缩模型体积,计算时依旧是dequant到input.dtype做计算。
TRT-LLM的量化:W4A(表示weight为4bit,输入数据即activation为fp)。
LLM模型推理,性能损耗大头在data 搬移,即memory bound,compute bound占比较少。
TRT-LLM运行时内存可以通过一下参数调整,使用适合当前业务模型的参数即可。
TRT-LLM对于Batch Manager提供了.a文件,用于支持in-flight batching of requests,来较小队列中的数据排队时间,提高GPU利用率。
当前支持(0.7.1)的模型如下:
tensorrt llm需要进行源码编译安装,官方提供的方式为通过docker进行安装。
docker方式编译可以参考官方文档,此处做进一步说明。使用docker方式,会将依赖的各种编译工具和sdk都下载好,后面会详细分析一下docker的编译过程。
编译有2种包,一种是仅包含cpp的代码包,一种是cpp+python的wheel包。
docker的整个编译过程从如下命令开始:调用make,makefile在 docker/Makefile 下面,里面主要是调用了docker命令来进行构建。
后续非docker方式编译llm,也是基于上述docker编译。
一些小技巧:在编译llm过程中,会通过pip install一些python包,llm脚本中默认使用了NVIDIA的源,我们可以替换为国内的源,速度快一些。
整个过程就是将docker file中的过程拆解出来,直接执行,不通过docker来执行。
编译好的文件位于:build/tensorrt_llm-0.5.0-py3-none-any.whl。
默认编译选项下的一些编译配置信息如下:
以官方样例bloom为例:bloom example
核心在于:编译时使用的环境信息和运行时的环境信息要一致,如:python版本,cuda/cudnn/nccl/tensorrt等。卡神网源码
环境安装后以后,参考官方bloom样例,进行模型下载,样例执行即可。
最终生成的engine模型:
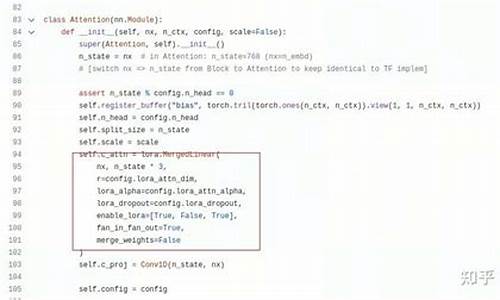
以chatglm2-6b模型为基础,进行lora微调后,对模型进行参数合并后,可以使用tensortrt-llm的example进行部署,合并后的模型的推理结果和合并前的模型的推理结果一致。
lora的源码不在赘述,主要看一下lora模型参数是如何合并到base model中的:
lora模型如下:
base模型如下:
模型构建是指将python模型构建为tensort的engine格式的模型。
整体流程如下:
整体流程可以总结为:
可以看出,原理上和模型转换并没有区别,只是实现方式有差异而已。
pytorch模型参数如何加载在tensortrt-llm中?关于量化参数加载
1. 先提取fp格式的参数
2. 调用cpp的实现进行参数量化
整体而言,模型参数加载的关键在于:算子weight一一对应,拷贝复制。
每种模型,都需要搭建和pytorch严格一致的模型架构,并将算子weight严格对应的加载到tensortrt-llm模型中
即:关键点在于:熟悉原始pytorch模型结构和参数保存方式,熟悉tensorrt-llm的模型结构和参数设定方法。
模型构建成功后,有两个文件:config.json文件推理时会用到,主要内容如下:模型参数信息和plugin信息。
在模型构建好后,就可以做模型推理,推理流程如下:
TRT-LLM Python Runtime分析
1. load_tokenizer
2. parse_input
基于 tokenizer 对输入的text做分词,得到分词的id
3. runner选择&模型加载
4.推理
5. 内存管理
TRT-layer实现举例
(1)对tensorrt的接口调用:以cast算子为例:functional.py是对TensorRT python API接口的调用
调用tensorrt接口完成一次推理计算
(2)TRT-LLM python侧对cpp侧的调用
调到cpp侧后,就会调用cpp侧的cuda kernel
trtllm更新快,用了一些高版本的python特性,新的trtllm版本在python3.8上,不一定能跑起来
腾讯T2I-adapter源码分析(1)-运行源码跑训练
稳定扩散、midjourney等AI绘图技术,为人们带来了令人惊叹的效果,不禁让人感叹技术发展的日新月异。然而,AI绘图的可控性一直不是很好,通过prompt描述词来操控图像很难做到随心所欲。为了使AI绘制的图像更具可控性,Controlnet、T2I-adapter等技术应运而生。本系列文章将从T2I-adapter的源码出发,分析其实现方法。
本篇是第一篇,主要介绍源码的运行方法,后续两篇将以深度图为例,分别分析推理部分和训练部分的代码。分析T2I-Adapter,也是为了继续研究我一直在研究的课题:“AI生成同一人物不同动作”,例如:罗培羽:stable-diffusion生成同一人物不同动作的尝试(多姿势图),Controlnet、T2I-adapter给了我一些灵感,后续将进行尝试。
T2I-Adapter论文地址如下,它与controlnet类似,都是在原模型增加一个旁路,然后对推理结果求和。
T2I-Adapter和controlnet有两个主要的不同点,从图中可见,其一是在unet的编码阶段增加参数,而controlnet主要是解码阶段;其二是controlnet复制unit的上半部结构,而T2I-Adapter使用不同的模型结构。由于采用较小的模型,因此T2I-Adapter的模型较小,默认下占用M左右,而controlnet模型一般要5G空间。
首先确保机器上装有3.6版本以上python,然后把代码clone下来。随后安装依赖项,打开requirements.txt,可以看到依赖项的内容。然后下载示例,下载的会放到examples目录下。接着下载sd模型到model目录下,再下载T2I-Adapter的模型到目录下,模型可以按需到huggingface.co/TencentA...下载。这里我下载了depth和openpose。sd模型除了上述的v1-5,也还下载了sd-v1-4.ckpt。
根据文档,尝试运行一个由深度图生成的例子,下图的左侧是深度图,提示语是"desk, best quality, extremely detailed",右侧是生成出来的。运行过程比较艰辛,一开始在一台8G显存的服务器上跑,显存不够;重新搭环境在一台G显存的服务器上跑,还是不够;最后用一台G显存的服务器,终于运行起来了。
接下来尝试跑openpose的例子,下图左侧是骨架图,提示词为"Iron man, high-quality, high-res",右侧是生成的图像。
既然能跑推理,那么尝试跑训练。为了后续修改代码运行,目标是准备一点点数据把训练代码跑起来,至于训练的效果不是当前关注的。程序中也有训练的脚步,我们以训练深度图条件为例,来运行train_depth.py。
显然,习惯了,会有一些问题没法直接运行,需要先做两步工作。准备训练数据,分析代码,定位到ldm/data/dataset_depth.py,反推它的数据集结构,然后准备对应数据。先创建文件datasets/laion_depth_meta_v1.txt,用于存放数据文件的地址,由于只是测试,我就只添加两行。然后准备,图中的.png和.png是结果图,.depth.png和.depth.png是深度图,.txt和.txt是对应的文本描述。
文本描述如下,都只是为了把代码跑起来而做的简单设置。设置环境变量,由于T2I-Adapter使用多卡训练,显然我也没这个环境,因此要让它在单机上跑。而代码中也会获取一些环境变量,因此做简单的设置。
做好准备工作,可以运行程序了,出于硬件条件限制,只能把batch size设置为1。在A显卡跑了约8小时,完成,按默认的配置,模型保存experiments/train_depth/models/model_ad_.pth。那么,使用训练出来的模型试试效果,能生成如下(此处只是为了跑起来代码,用训练集来测试),验证了可以跑起来。
运行起来,但这还不够,我们还得看看代码是怎么写法,下一篇见。
PS:《直观理解AI博弈原理》是笔者写的一篇长文,从五子棋、象棋、围棋的AI演进讲起,从深度遍历、MAX-MIN剪枝再到蒙特卡罗树搜索,一步步介绍AI博弈的原理,而后引出强化学习方法,通俗易懂地介绍AlphaGo围棋、星际争霸强化学习AI、王者荣耀AI的一些强化学习要点,值得推荐。
AUTOMATIC的webui是近期很流行的stable-diffusion应用,它集合stable-diffusion各项常用功能,还通过扩展的形式支持controlnet、lora等技术,我们也分析了它的源码实现,写了一系列文章。
物联网Lora技术应用有哪些?Lora无线通讯模块有什么优缺点?
Lora无线通讯技术在物联网领域应用广泛,从共享单车到智能水电表,Lora都扮演着重要角色。Lora无线技术凭借其独特的特性,成为低功耗广域网(LPWAN)的首选方案之一。
首先,Lora的低功耗特性是其一大优势。接收电流仅为mA,睡眠电流小于nA,这大大延长了电池的使用寿命,减少了电池供电设备的功耗。
其次,Lora的传输距离远,与传统无线技术相比,其在低速空旷条件下的传输距离可达公里。这是因为Lora解调信号的信噪比与-dB,远高于调频制式的dB,使得其范围和距离显著扩大。
在抗干扰能力方面,Lora采用扩频技术,通过高扩频因子提高了无线通讯的抗干扰能力。即使在同一频率下同时发送信号,也不会相互干扰。
Lora的无线穿透力也更强,Mhz无线传输频率下的发射功率下,其穿透能力比传统ASK技术提高了5倍以上。
关于Lora的无线通讯速率,它支持半双工通讯,速率范围从bps到5.4kbps。这足以支持无线升级设备固件,满足物联网应用的需求。
在产品开发应用中,Lora模块为工程师提供了便利。产品开发时只需按照模块接口和文档完成设计,大大简化了产品开发流程。模块集成的无线通讯协议栈,减少了开发者需要处理的繁琐工作。
使用Lora模块进行产品开发的优势还包括更短的开发周期和更省心的产品调试。当无线通讯出现问题时,厂家会提供支持,快速解决处理。
然而,市面上的Lora模块通用性较强,但可能无法完全满足特定产品的尺寸、功能和接口需求。如果找到合适的模块困难,企业可以选择向模块厂家定制,或自行研发。
针对Lora模块的开发与设计,无际单片机编程提供了全面的教程和开发板,深入解析了芯片级的开发流程,有助于节约成本。
此外,无际单片机还分享了单片机入门到高级教程工具包,以及个热门项目源码、原理图、PCB设计和说明文档,非常适合初学者和进阶学习者。
获取这份资料包和加入单片机交流群,可以点击下方卡片扫码免费领取,或者联系无际单片机获取更多技术支持和学习资源。
邮票孔LoRa模组选型指南
本文档提供HL LoRa模组的详细信息,包括硬件应用接口、电路连接、射频接口以及电气性能等。通过阅读本文档,用户可快速掌握HL模组的接口定义、尺寸与工作特性,以及如何利用其设计物联网通讯方案。用户可通过芮捷官网、淘宝店或技术支持获取最新资料。
HL是一款具备低功耗与紧凑设计的LoRa串口透传通信模组,专为工业级标准设计,采用高性能芯片方案实现LoRa网络数据传输。在应用中,HL模组能显著减少产品开发时间。模组运行在嵌入式RTOS操作系统下,支持多任务实时处理、内置看门狗与数据缓冲机制,确保系统稳定性。同时,HL支持直接二次开发,SDK源码可在gitee.com或github.com获取。
HL模组具备多种特性,包括邮票孔封装、天线支持IPEX或邮票孔方式、可调发射功率至dBm、接收灵敏度低至-dBm、链路预算高达dBm、低功耗设计(空闲1mA,休眠2uA)、支持低功耗串口与AT指令配置、定频及跳频模式、AES 数据加密、传输距离可达3~5km以及支持多种收发模式。此模组特别适用于自动抄表、水/电计量、家庭/楼宇自动化、工业监控、无线报警与安全系统等领域。
HL模组采用邮票孔封装设计,方便集成至产品中,无需射频设计经验。该模组共有个引脚,详细描述见表格。其电气特性包括极限参数、工作参数、直流电气特性与射频参数,注意超过绝对最大额定值可能导致模组损坏。模组的电源电压输入范围为2.2V至3.7V,推荐使用LDO电源以确保性能稳定性。模组峰值电流最大mA,电源设计需留有余量以适应不同应用需求。模组的GPIO引脚用于指示RF状态,辅助调试。UART串口支持低功耗串口传输,波特率范围为bps至bps,当波特率不高于bps时,模组可在休眠状态下接收与响应数据,无需额外唤醒操作。模组的复位与启动选择通过BOOT引脚控制,DIO与CLK用于调试升级,SDA/TXD与SCL/RXD为保留引脚,ADC0与ADC1为模拟信号输入口,Wake_UP用于唤醒模组,AT配置通过AT引脚或发送特殊字符进入模式,模组支持IPEX与邮票孔两种天线接口。
HL模组的尺寸规格包括模组尺寸与推荐的SMT封装尺寸,具体参数见文档。订货代码信息包含型号说明,用于用户识别与订购模组。