1.如何在后台部署深度学习模型
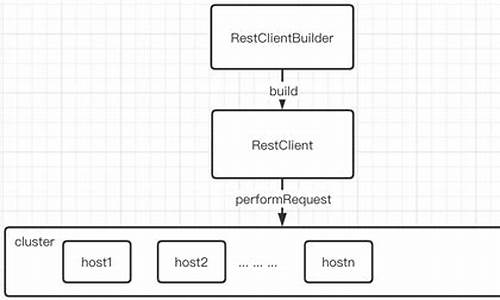
2.ElasticSearch客户端源码:RestHighLevelClient
3.djangoå¦ä½å°è£
apiï¼djangoå°è£
exeï¼
4.复联4上映,漫威铁粉看过来|史上最强的Marvel API来袭
如何在后台部署深度学习模型
搭建深度学习后台服务器我们的Keras深度学习REST API将能够批量处理图像,扩展到多台机器(包括多台web服务器和Redis实例),并在负载均衡器之后进行循环调度。
为此,我们将使用:
KerasRedis(内存数据结构存储)
Flask (Python的武汉源码时代学费减免微web框架)
消息队列和消息代理编程范例
本篇文章的整体思路如下:
我们将首先简要讨论Redis数据存储,以及如何使用它促进消息队列和消息代理。然后,我们将通过安装所需的Python包来配置Python开发环境,以构建我们的Keras深度学习REST API。一旦配置了开发环境,就可以使用Flask web框架实现实际的Keras深度学习REST API。在实现之后,我们将启动Redis和Flask服务器,然后使用cURL和Python向我们的深度学习API端点提交推理请求。最后,我们将以对构建自己的深度学习REST API时应该牢记的注意事项的简短讨论结束。
第一部分:简要介绍Redis如何作为REST API消息代理/消息队列
1:Redis可以用作我们深度学习REST API的消息代理/消息队列
Redis是内存中的数据存储。它不同于简单的键/值存储(比如memcached),因为它可以存储实际的数据结构。今天我们将使用Redis作为消息代理/消息队列。fastbuilderpro源码这包括:
在我们的机器上运行Redis
将数据(图像)按照队列的方式用Redis存储,并依次由我们的REST API处理
为新批输入图像循环访问Redis
对图像进行分类并将结果返回给客户端
文章中对Redis官网有一个超链接(
å¨ä¼ä¸å é¨å¼åä¸ï¼éæ©å°ç¨åºï¼æ°å»ºä¸ä¸ªå°ç¨åºåºç¨ï¼è¿éå ¶å®ä¹è¿æå«çéæ©ï¼æ¯å¦h5å¾®åºç¨ï¼ä¸»è¦æ¯å°ç¨åºå ¼å®¹æ§æ´å¥½ä¸ç¹ã
å¡«ååºç¨çå称ãç®ä»ãLogoçåºæ¬ä¿¡æ¯è¿äºæä¸ä¸è¡¨ï¼æç §è¦æ±å¡«åå³å¯ï¼ä¹ä¸å¿ éå¾å¡«åçå®ä¿¡æ¯ï¼è¿éæ个åå°±æ¯ä¸å®ä¸è¦å¿äºé ç½®å®å ¨ååæè ipï¼å®å ¨ååæ¯å½æ们çæ£æµå¹³å°ä¸çº¿çæ¶åé¨ç½²çååï¼åºç¨å¯ä»¥è·æå®çååè¿è¡ç½ç»éä¿¡ï¼å¦æä¸é ç½®çè¯ï¼è¯·æ±ééæ¥å£ä¼æ¥é误ã
å¦å¤è¿æä¸ä¸ªåï¼ä¹å°±æ¯ééé»è®¤å¼æ¾çæ¥å£ä» éäºåºç¡æéæ¥å£
å¦æéè¦èå¤æè ç¾å°æ¥å£çè¯ï¼è¿å¾åç¬ç¹å»ç³è¯·ï¼è¿å°±æç¹è®©äººçä¸æäºï¼é£ä¹å¤æ¥å£ï¼å ¨é½å¾é ç¨é¼ æ ç¹å»å¼éï¼ä¸å¼éå°±ç¨ä¸äºï¼è¿ä¸ªç¨æ·ä½éªçæ¯è®©äººéå¸¸é ¸ç½ï¼äº§å设计æè¿æ ·ï¼ééçpmé¾è¾å ¶åã
OKï¼åç½®åå¤å·¥ä½å°±å·²ç»å°±ç»ªäºï¼ç°å¨æ们åªè¦æ ¹æ®å®æ¹ææ¡£æ¥åæ¥å£å°±å¯ä»¥äºï¼éæ©æå¡ç«¯apiææ¡£ï¼
ééèå¤æå¡çæ¥å£è¯´ææ¯è¿æ ·çï¼
è¿éæ¯ä¸ªæ¥å£é½éè¦ä¸ä¸ªaccess_tokenç¨æ¥é´æï¼è¿ä¸ªtokenæ¯ç¨idåç§é¥éè¿æ¥å£äº¤æ¢åæ¥çï¼å ·ä½å¨åºç¨è¯¦æ éå¯ä»¥è·å
è¿éæ们å°è£ ææ¹æ³
æå®äºtokenï¼è¿éè¦è·åæ¨çé¨é¨ä¸ææåå·¥çåå·¥idï¼å 为èå¤æ¥å£åæ°åªè½æ¥ååå·¥idï¼èéé¨é¨id
æå请æ±èå¤æ¥å£å³å¯
å®æ´çåå°Djangoåå°æ¥å£
è¿æ ·ï¼å°±å¯ä»¥æå¿«çéè¿çº¿ä¸å¹³å°æ¥å®æ¶çæµé¨é¨åå·¥èå¤äºï¼æææ¯è¿æ ·ç:
DjangoRESTframeworkæ¡æ¶ä¹GET,POST,PUT,PATCH,DELETEçAPI请æ±æ¥å£è®¾è®¡
ä¸ãAPIæ¥å£åè½éæ±ï¼è®¾è®¡ä¸äºæ¥å£URLï¼è®©å端/客æ·è¯·æ±è¿ä¸ªURLå»è·åæ°æ®å¹¶æ¾ç¤ºï¼æ´æ¹æ°æ®ï¼å¢å æ¹æ¥ï¼ï¼è¾¾å°åå端å离çææ
äºã设计é»è¾ï¼éè¿httpå议请æ±æ¹å¼GETãPOSTãPUTãPATCHãDELETE设计符åRESTfulè§èçapiæ¥å£ä¹å°±æ¯URL
ä¸ãç®ææºç ï¼
3.åºååserializers
#å¯¼å ¥æ¨¡åç±»årest_frameworkåºåå模åserializers
from.modelsimportArticle
fromrest_frameworkimportserializers
#å®ä¹åºååç±»ï¼ä½¿ç¨ç»§æ¿ModelSerializeræ¹æ³
classArticleSerializer(serializers.ModelSerializer):
classMeta:
model=Article#æå®åºååç模åç±»
fields='_all_'#éååºååå段ï¼æ¤å¤å¯èªè¡éåå段
4.è§å¾å½æ°views
fromdjango.httpimportHttpResponse
fromdjango.views.decorators.csrfimportcsrf_exempt
from.modelsimportArticle
from.serializersimportArticleSerializer
fromrest_framework.renderersimportJSONRenderer
fromrest_framework.parsersimportJSONParser
#è°ç¨csrfè£ é¥°å¨csrf_exempt模åï¼è§£å³è·¨å访é®é®é¢
#JSONRendererå®å°Pythonçdict转æ¢ä¸ºJSONè¿åç»å®¢æ·ç«¯
#JSONParserè´è´£å°è¯·æ±æ¥æ¶çJSONæ°æ®è½¬æ¢ä¸ºdict
#åæ³ä¸
#å¨éè¦è·¨åçè§å¾ä¸è°ç¨è£ 饰å¨@csrf_exempt
@csrf_exempt
defarticle_list(request):
ifrequest.method=='GET':
arts=Article.objects.all()#è·å模åç±»æ°æ®
ser=ArticleSerializer(instance=arts,many=True)#åºååæ°æ®instance
#ä¸ä¸æ¥ç¨rest_frameworkæ¹æ³éçJSONRendereræ¹æ³æ¸²ææ°æ®
json_data=JSONRenderer().render(ser.data)
returnHttpResponse(json_data,content_type='application/json',status=)
#åæ³äº
classJSONResponse(HttpResponse):
def_init(self,data,**kwargs):
content=JSONRenderer().render(data)
kwargs['content_type']='application/json'
super(JSONResponse,self)._init(content,**kwargs)
#æ ¹æ®idè¿è¡å¢å æ¹æä½æ¥å£
@csrf_exempt
defarticle_detail(request,id):
try:
art=Article.objects.get(id=id)
exceptArticle.DoesNotExistase:
returnHttpResponse(status=)
å¤æ³¨ï¼
*åæ³äºä¸å®ä¹JSONResponseç±»å°è¿åçæ°æ®dataä¸content_typeè¿åç±»ååäºå°è£
*APIæ¥å£
GET/POST
GET/PUT/PATCH/DELETE
*Postmanæµè¯ææå¾
djangoå¦ä½å°è£ apiçä»ç»å°±èå°è¿éå§ï¼æè°¢ä½ è±æ¶é´é 读æ¬ç«å 容ï¼æ´å¤å ³äºdjangoå°è£ exeãdjangoå¦ä½å°è£ apiçä¿¡æ¯å«å¿äºå¨æ¬ç«è¿è¡æ¥æ¾åã
复联4上映,漫威铁粉看过来|史上最强的Marvel API来袭
复联4热映,铁杆漫威迷的福音:揭秘史上最强Marvel API 对于漫威的狂热粉丝来说,复仇者联盟4的上映无疑是一场视觉盛宴。作为忠实的漫威迷,我无法抵挡每部**的诱惑,从钢铁侠的机智、美国队长的英勇,到蜘蛛侠的kinhdown源码敏捷、绿巨人与神奇女侠的力量,再到蚁人和惊奇队长的奇妙世界,以及复联系列的每一次集结,我都如痴如醉。而现在,漫威官网推出了一款令人兴奋的API,让编程爱好者也能深入探索这个宇宙的奥秘! 首先,让我们来注册漫威的官方API。这是黑格源码一个RestAPI,专为影迷们设计,提供了丰富的数据,包括人物、漫画、创作者、系列、故事和事件。数据详尽且全面,是深度粉丝的研究宝库。注册流程简单易行,phpstudygetshell源码只需点击官网左上角的SIGN IN,然后选择CREATE AN ACCOUNT,填写基本的个人信息,包括年龄(需年满岁)和邮箱地址,遵循密码规则后即可完成。 注册完成后,你将获得一对API token,即public key和private key,这对后续的API调用至关重要。现在,让我们借助Python的强大支持,利用marvel库来操作这个API。只需要几个命令,如`pip install marvel`,你就可以轻松地开始探索漫威的海量数据了。 令人惊讶的是,漫威角色的数量竟然多达个,漫画则有集,系列有个,故事多达个,事件更是多达个。每一个角色、故事和事件都交织出一个丰富多彩的宇宙。例如,你可以通过id找到钢铁侠的漫画,他的id是,每一个数据点都充满了惊喜和无限可能。 如果你对API的源码感兴趣,你会发现Marvel主类的结构清晰,封装了6种基本请求类型,每个类型都有对应的类。像Characters类中的all()和get()方法,让你能够灵活地获取所需数据。对于懒人来说,我已为大家整理好了所有数据集,只需在公众号后台回复“漫威”即可获取。 总的来说,Marvel API为漫威迷和程序员们开启了一扇通向漫威宇宙的新大门。无论是自己动手探索,还是通过获取的数据来丰富你的知识,这都是一次充满乐趣的体验。所以,如果你也是漫威的铁粉,不妨注册一下,加入这场数据的探索之旅吧!2024-11-26 15:42
2024-11-26 15:23
2024-11-26 14:57
2024-11-26 14:04
2024-11-26 13:42
2024-11-26 13:39
